Les doublons dans une base de données prennent de la place inutilement et peuvent causer des erreurs sur un site web ou une application. Dans un précédent article des requêtes SQL pour trouver les doublons étaient présentées. Cet article-ci présente une requête pour supprimer les doublons tout en conservant une ligne.
ATTENTION : avant de commencer à exécuter la requête de suppression, il faut penser à faire un backup (cf. une sauvegarde) de la table concernée. Dans le pire des cas, il sera possible de la ré-installer.
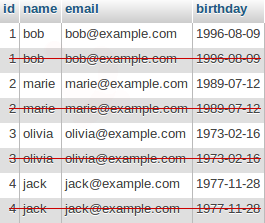
Supprimer les doublons d’une table
Rappel : requête pour trouver les doublons
Avant de vouloir supprimer les éventuels doublons, il faut commencer par vérifier s’il y en a. La requête suivante est à utiliser en remplaçant les champs 1 à 3 par les champs de votre choix qui doivent servir de référentiel pour trouver les lignes dupliquées.
SELECT COUNT(*) AS nbr_doublon, champ1, champ2, champ3 FROM table GROUP BY champ1, champ2, champ3 HAVING COUNT(*) > 1
Attention, selon le type de lignes dupliquées, il ne faut peut-être pas faire de recherche en utilisant les champs qui servent de timestamp (exemple : un champ DATETIME).
Requête pour supprimer les doublons
Si la requête précédente à bien retournée des résultats considéré comme des doublons, alors il est temps de passer à l’étape suivante pour préparer la suppression. La requête ci-dessous sert à supprimer les lignes en trop qui possèdent les même données dans les colonnes “champ1” à “champ3” (à personnaliser).
DELETE FROM table
LEFT OUTER JOIN (
SELECT MIN(id) as id, champ1, champ2, champ3
FROM table
GROUP BY champ1, champ2, champ3
) as t1
ON table.id = t1.id
WHERE t1.id IS NULLAttention, il y a plusieurs choses à savoir à propos de cette requête :
- Le champ “id” est à personnaliser selon le nom de la colonne de votre propre table.
- La requête va conserver la ligne avec l’ID le plus petit car la fonction MIN() est utilisée. Il est possible de conserver la requête avec l’ID le plus grand en utilisant à la place la fonction MAX().
- Cette requête assume qu’aucun champ n’est NULL.
Solution n°2
DELETE t1 FROM table AS t1, table AS t2 WHERE t1.id > t2.id AND t1.column1 = t2.column1 AND t1.column2 = t2.column2 AND t1.column3 = t2.column3
Vérifier
Il faut songer à vérifier que tout s’est bien passé après avoir supprimé toutes ces lignes. Il est possible de contrôler qu’il n’y a plus de doublons. S’il y en a toujours, c’est le moment de recommencer en corrigeant la requête. Si au contraire trop de lignes ont été supprimées, il faut ré-installer la sauvegarde pour ne pas perdre inutilement des lignes.
A noter : il existe d’autres manières de supprimer les doublons. N’hésitez pas à utiliser une autre technique si vous n’êtes pas à l’aise avec celle-ci.
Bonjour,
Et merci pour les requêtes, pour trouver les doublons cela fonctionne très bien, pour les supprimer voici le message :
debug : #1064 – You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘LEFT OUTER JOIN ( SELECT MIN(ID) as ID, post_title, post_content, post_e’ at line 2{“success”:false,”error”:”
#1064 – You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘LEFT OUTER JOIN (\n SELECT MIN(ID) as ID, post_title, post_content, post_e’ at line 2″}
Si vous pouviez m’aider.
Nicolas
Bonjour,
la requête delete ne fonctionnait pas chez moi je l’ai faite ainsi, en ajoutant table avant le from:
DELETE table FROM table
LEFT OUTER JOIN (
SELECT MIN(id) as id, champ1, champ2, champ3
FROM table
GROUP BY champ1, champ2, champ3
) as t1
ON table.id = t1.id
WHERE t1.id IS NULL
@develle c’est a fonctionné chez toi ? parce que moi aucune fonctionne :(
Excellent… j’ai aussi ajouter le nom de la table avant le FROM
DELETE table FROM table
LEFT OUTER JOIN (
SELECT MIN(id) as id, champ1, champ2, champ3
FROM table
GROUP BY champ1, champ2, champ3
) as t1
ON table.id = t1.id
WHERE t1.id IS NULL
fonctionne très bien.
Bonjour,
Pourriez-vous m’écrire la requête sql pour supprimer les doublons dans ma table mais uniquement les doublons du champ `meta_key`
Voici ma table :
CREATE TABLE IF NOT EXISTS `wp_usermeta` (
`umeta_id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`user_id` bigint(20) unsigned NOT NULL DEFAULT ‘0’,
`meta_key` varchar(255) DEFAULT NULL,
`meta_value` longtext,
PRIMARY KEY (`umeta_id`),
KEY `user_id` (`user_id`),
KEY `meta_key` (`meta_key`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=18907 ;
D’avance merci :-)
DELETE table FROM table
Et bien c’est incroyable, j’ai pédalé des heures
2 x la TABLE et ça marche………………………….
C’est ici que je l’ai trouvé, MERCI
Salut,
J’utilise postgresql en association avec postgis
mon champs id = gid
j’ai effectué la requête écrite précédemment
DELETE
FROM “BOCAGE_table_complete”
LEFT OUTER JOIN (
SELECT MIN(“gid”) as “gid”, “DATE_TRVX”, “LONGUEUR”, “NOM_INTERL”
FROM “BOCAGE_table_complete”
GROUP BY “DATE_TRVX”, “LONGUEUR”, “NOM_INTERL”
) as t1
ON table.gid = t1.gid
WHERE t1.gid IS NULL
Celle ci ne marche pas.
J’ai mis la table avant et après le FROM :
DELETE “BOCAGE_table_complete”
FROM “BOCAGE_table_complete”
LEFT OUTER JOIN (
SELECT MIN(“gid”) as “gid”, “DATE_TRVX”, “LONGUEUR”, “NOM_INTERL”
FROM “BOCAGE_table_complete”
GROUP BY “DATE_TRVX”, “LONGUEUR”, “NOM_INTERL”
) as t1
ON table.gid = t1.gid
WHERE t1.gid IS NULL
ça ne marche toujours pas.
Est ce que cette requête fonctionne avec postgresql ? est ce quelqu’un voit où se trouve le problème ?
Bonjour,
je ne souhaite pas effacer les doublons, mais les identifier comme tels, donc mettre à jour un champ status. Ma requete ci-dessous ne fonctionne pas, avez-vous une idée de la raison:
update ma_table
LEFT OUTER JOIN (
SELECT MIN(id) as id, username
FROM ma_table
GROUP BY username
) as t1
ON table.id = t1.id
WHERE t1.id IS NULL
set status = ‘DUPLICATE’
avec ma_table contenant id (clé), username, status
une petite aide serait vraiment appréciée :) merci
faire une copie dans une table temporaire avec un select distinct et le tour est joué sans prise de tête.
cordialement.
Merci Tony.